
Python中有大量的爬虫框架来实现网络内容爬取,但是实现一些静态的内容爬虫往往只需要一些简单的库。我最近有一个需求是爬取一个语言网站的专栏。网上泰语的学习资料非常少,而这个网站的‘每日泰语词汇’栏目我尤其喜欢。但是在手机上用微信公众号一页一页翻很麻烦,又不能汇总,所以我希望能一次性抓取下这个栏目的网页版的每个文章标题和链接,然后放进一个表格中。
New Update
在一段时间后,对爬虫进行了一次迭代。主要针对之前的两个问题
- 没有采用面向对象式编程,代码复用性差,结构混乱。
- 只解析了链接,没有直接对链接内容进行直接分析。
这次迭代通过三个函数分别从专业页到内容页进行了文本的存储和解析,并把最终的结果按照文章的标题存储为html文件等待进一步处理。
import requests
from bs4 import BeautifulSoup
import urllib
def get_page(): # 专题页url
page_num = input('pls enter the page num: ')
page_list = []
for page in range(1, int(page_num) + 1):
page_list.append('https://th.hujiang.com/new/c19020/page' + str(page))
return page_list
def get_html(): # 专题页文章url
urls = get_page()
articles = [] # 生成要读取的文章url列表
for url in urls:
article_url = requests.get(url)
soup = BeautifulSoup(article_url.text, 'html.parser') # 解析专题页
for news in soup.find_all('a', {'class': 'list-item-title'}): # 找到专题页中的文章链接
articles.append('https://th.hujiang.com' + news.get('href'))
return articles
def parser_url(): # 从文章url中提取标题和正文的字典
result = get_html()
content = dict()
for url in result:
response = urllib.request.urlopen(url)
soup = BeautifulSoup(response, 'html.parser') # 解析url
contents = soup.find("div", class_="article-content")
try:
contents.img.extract() #去除正文中的图片
except:
print('extract failed, no photos')
title = soup.find("h1", class_="title").text # 仅保留所需的标题“每日一词”
titleflag = '每日一词'
if titleflag in str(title):
content[title] = [contents]
return content
def write_txt(): #写入文件
contents_dic = parser_url()
for i, kv in enumerate(contents_dic.items()):
fo = open(("%s.html" % kv[0]), "w")
fo.write(kv[0])
print('file %s is written' % kv[0])
fo.write(str(kv[1]))
fo.close()
print('done')
if __name__ == "__main__":
write_txt()
前版本
简单分析这个网站后,发现url不是用js翻页的,所以用for循环直接一页一页过一遍即可。所以整体的思路是把每一页的title和链接直接用BS定位,然后分两条写进一个文件就可以了。
import requests
from bs4 import BeautifulSoup
import time
def get_html(address, page):`
strhtml = requests.get(address)
soup = BeautifulSoup(strhtml.text, 'html.parser')
for news in soup.find_all('a', {'class': 'list-item-title'}):
result = news.get('title') + 'https://th.hujiang.com' + news.get('href') + '\n'
# print(result)
with open("cc.txt") as file:
f.write(result)
return
if __name__ == "__main__":
f = open("cc.txt", 'w')
for i in range(0, 2):
time.sleep(1)
link = 'https://th.hujiang.com/new/c19020/page' + str(i)
get_html(link, 0)
f.close()
虽然网站缺乏反爬机制,但是适当的暂停还是更加安全。因此翻页过程中我象征性加了1秒的延时。经过一段时间,最终结果如下。

最终爬出来大概7000多篇文章,此时如何管理和清洗这些链接成了关键。我也想过用内容提取每一页的内容,然后输出成PDF或是其他文件。但是这样不光数据量大,浏览和整理也成问题。最好的解决方案还是合并链接到标题,然后导入到知识管理软件里一键浏览器访问。
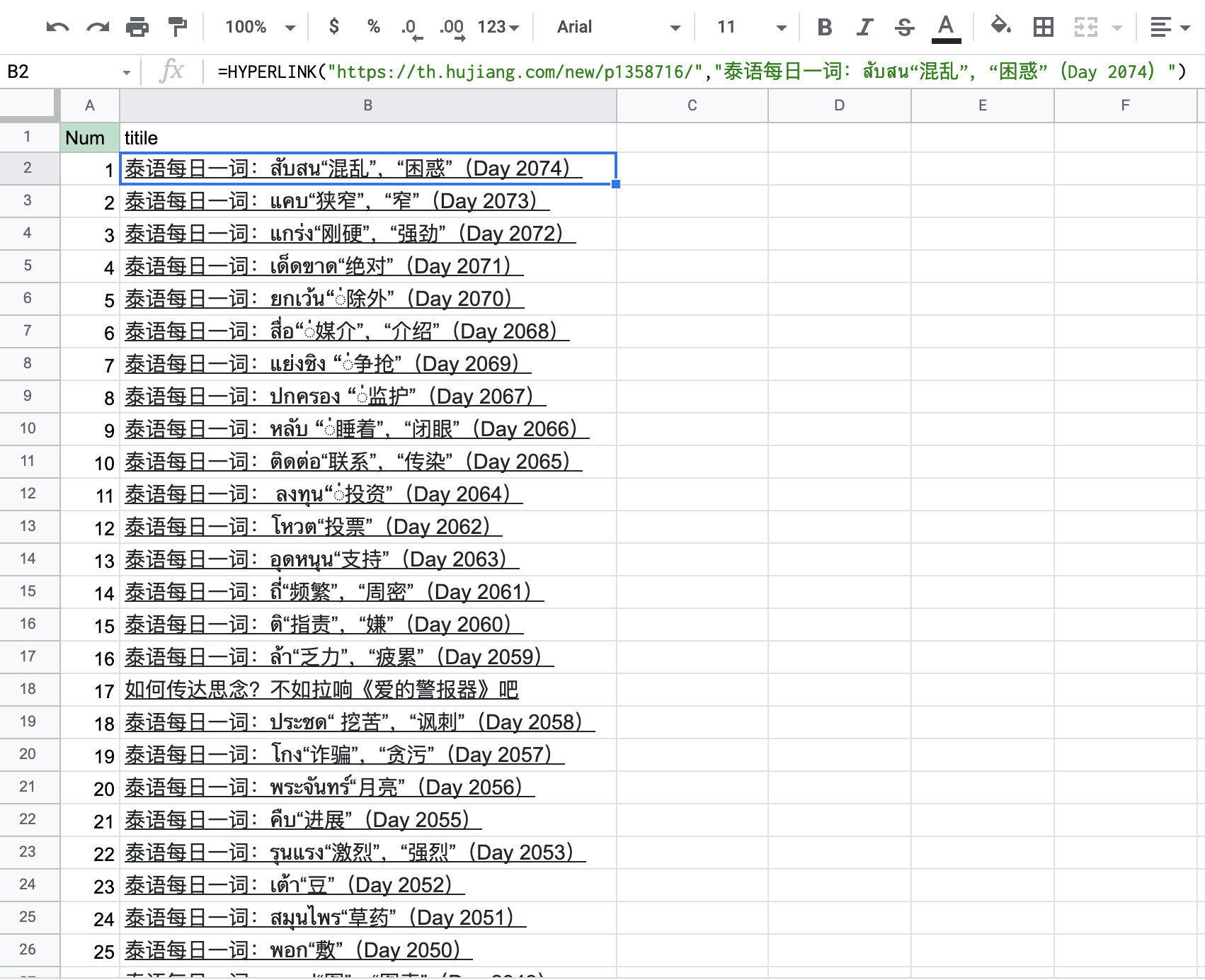
Notion承受不住太大的数据量,表格100行以上就出现预加载缓慢,而且在移动端上还容易误触。经过试验,Notion更适合以CSV的形式呈现这些数据。于是在EXCEL中重新整理数据,然后在副表中用函数一点点调用想阅读的部分,然后导出CSV到Notion就可以了。在手机端也可以凑合用。